1. Large Multimodal Models

Don't Settle Too Early: Self-Reflective Remasking for Diffusion Language Models
Zemin Huang, Yuhang Wang, Zhiyang Chen#, Guo-Jun Qi# (# corresponding author)
International Conference on Learning Representations (ICLR) 2026
We propose RemeDi, a new diffusion language model that introduces remasking allowing model to detect and resample low-confidence tokens during generation.
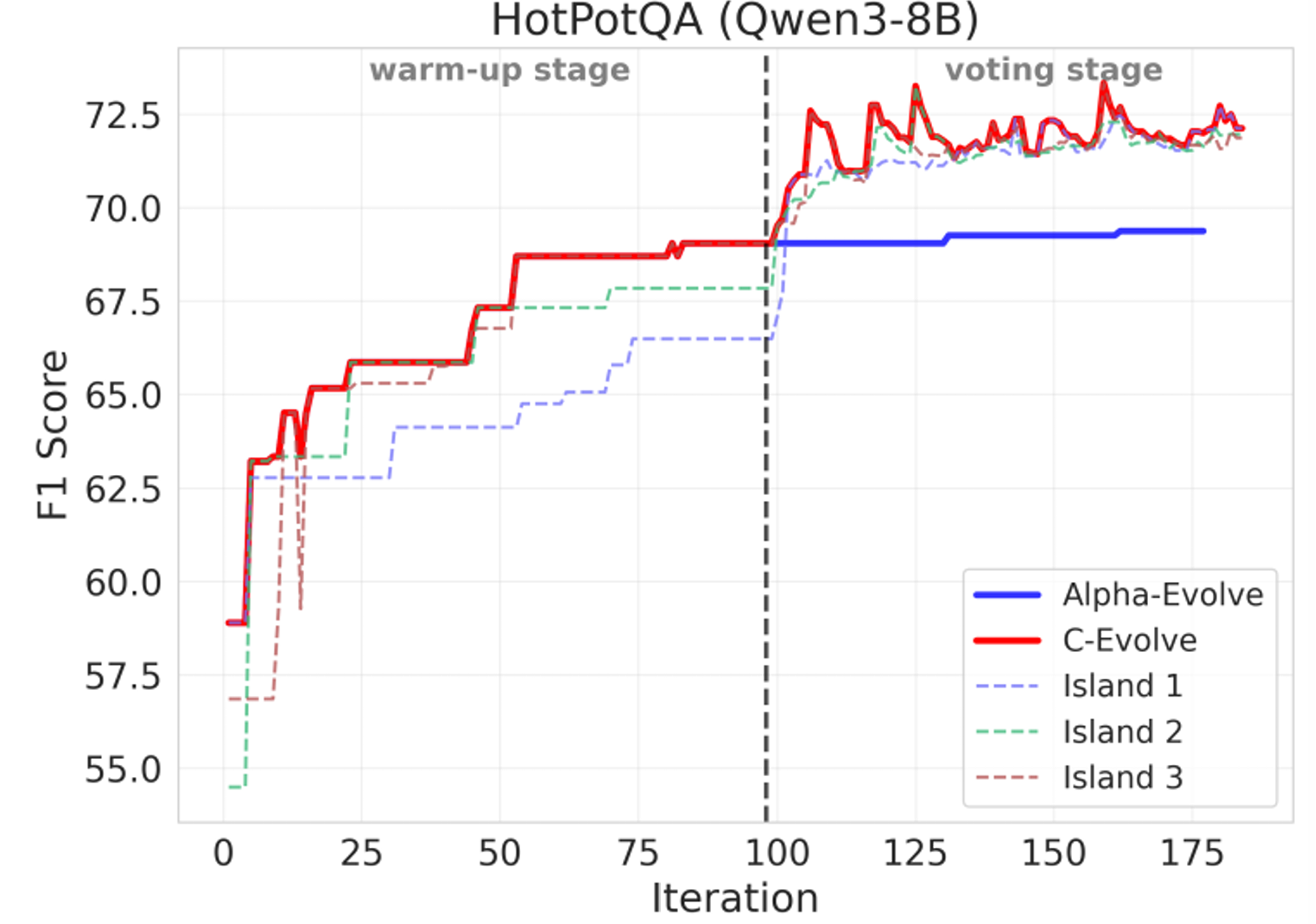
C-Evolve: Consensus-based Evolution for Prompt Groups
Tiancheng Li, Yuhang Wang, Zhiyang Chen, Zijun Wang, Liyuan Ma, Guo-Jun Qi
International Conference on Learning Representations (ICLR) 2026
An evolutionary algorithm that discovers a group of prompts whose aggregated outputs after majority voting achieve optimal performance.
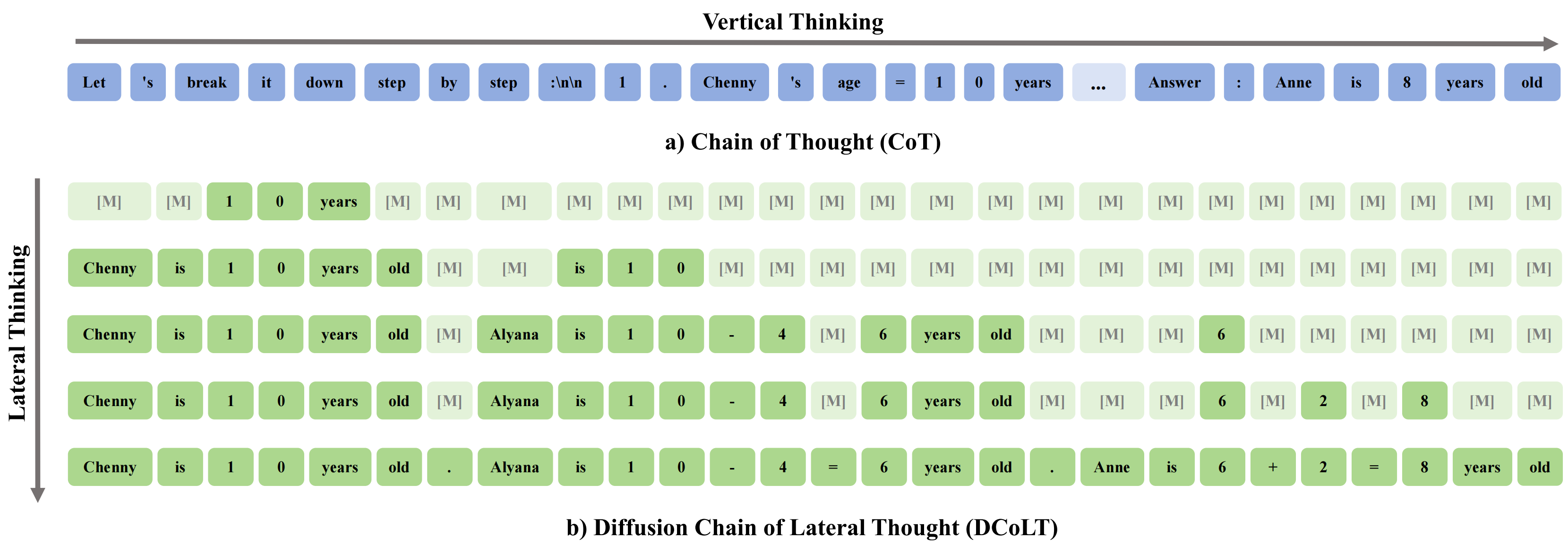
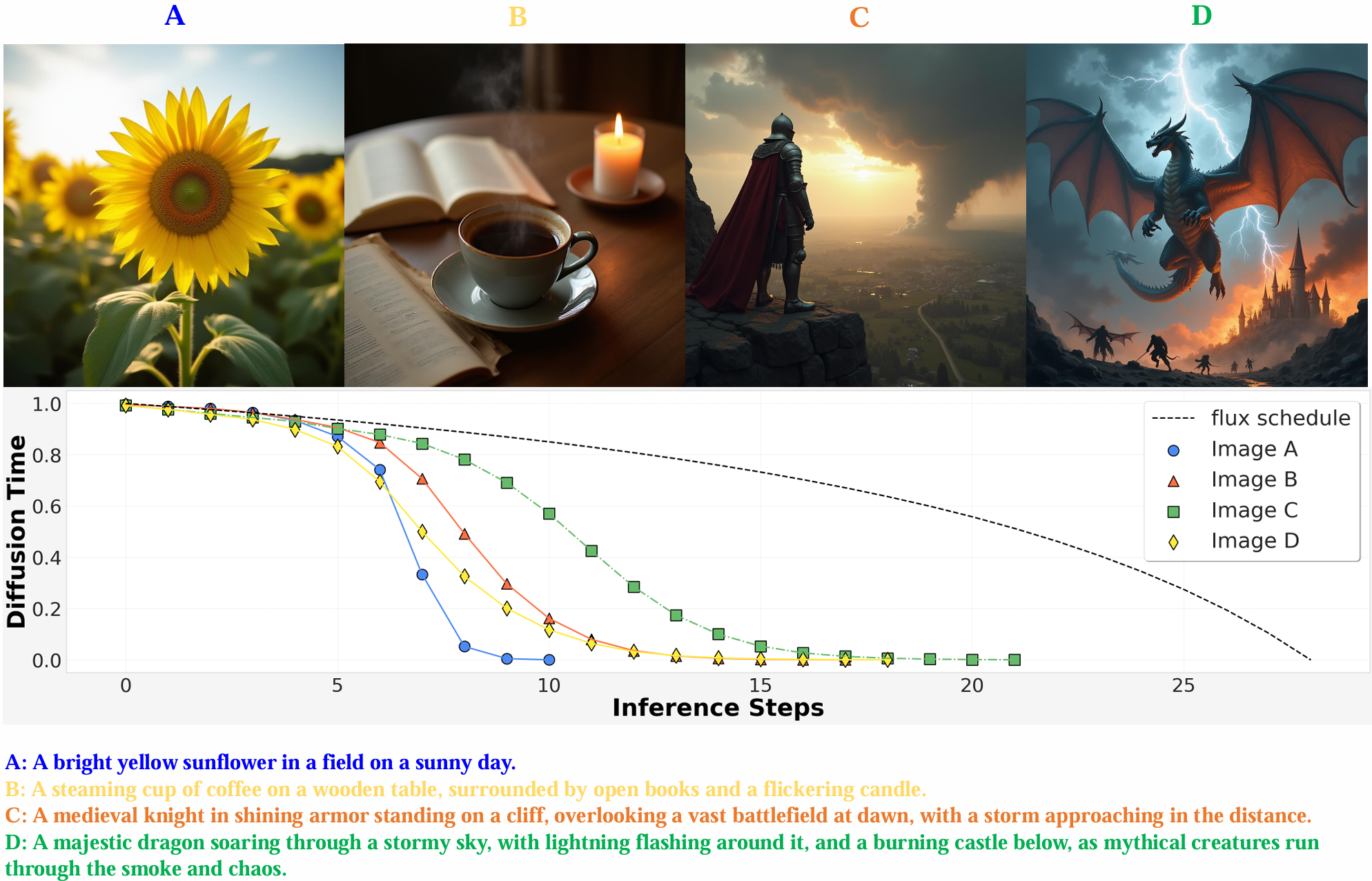
Schedule On the Fly: Diffusion Time Prediction for Faster and Better Image Generation
Zilyu Ye, Zhiyang Chen#, Tiancheng Li, Zemin Huang, Weijian Luo, Guo-Jun Qi# (# corresponding author)
Computer Vision and Pattern Recognition (CVPR) 2025
A Reforcement-Tuned Diffusion Model that can adjust the noise schedule on the fly, assigning fewer denoising steps on simple samples while more steps on complex ones.


Griffon: Spelling out All Object Locations at Any Granularity with Large Language Models
Yufei Zhan, Yousong Zhu, Zhiyang Chen, Fan Yang, Ming Tang, Jinqiao Wang
European Conference on Computer Vision (ECCV) 2024
Griffon is a Large Vision-Language Model that can accurately identify and locate objects of interest based on free-form texts. It is realized with a unified data format containing pure text and a novel language-prompted localization dataset, without introducing any specific tokens or expert models.

Openstory++: A Large-scale Dataset and Benchmark for Instance-aware Open-domain Visual Storytelling
Zilyu Ye, Jinxiu Liu, Ruotian Peng, Jinjin Cao, Zhiyang Chen, Yiyang Zhang, Ziwei Xuan, Mingyuan Zhou, Xiaoqian Shen, Mohamed Elhoseiny, Qi Liu, Guo-Jun Qi
arxiv 2024
OpenStory: A Large-Scale Open-Domain Dataset for Subject-Driven Visual Storytelling
Zilyu Ye, Jinxiu Liu, Jinjin Cao, Zhiyang Chen, Ziwei Xuan, Mingyuan Zhou, Qi Liu, Guo-Jun Qi
Computer Vision and Pattern Recognition (CVPR) Workshops 2024
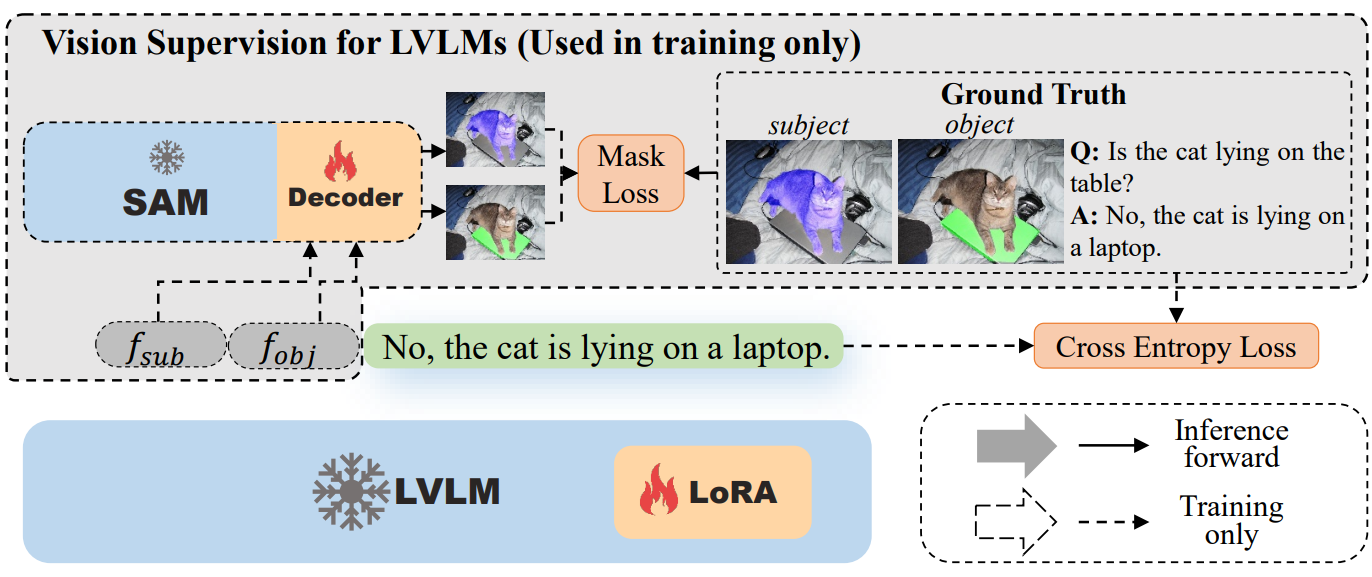
Mitigating Hallucination in Visual Language Models with Visual Supervision
Zhiyang Chen, Yousong Zhu, Yufei Zhan, Zhaowen Li, Chaoyang Zhao, Jinqiao Wang, Ming Tang
arxiv 2023
TBD
2. Foundation Vision Model
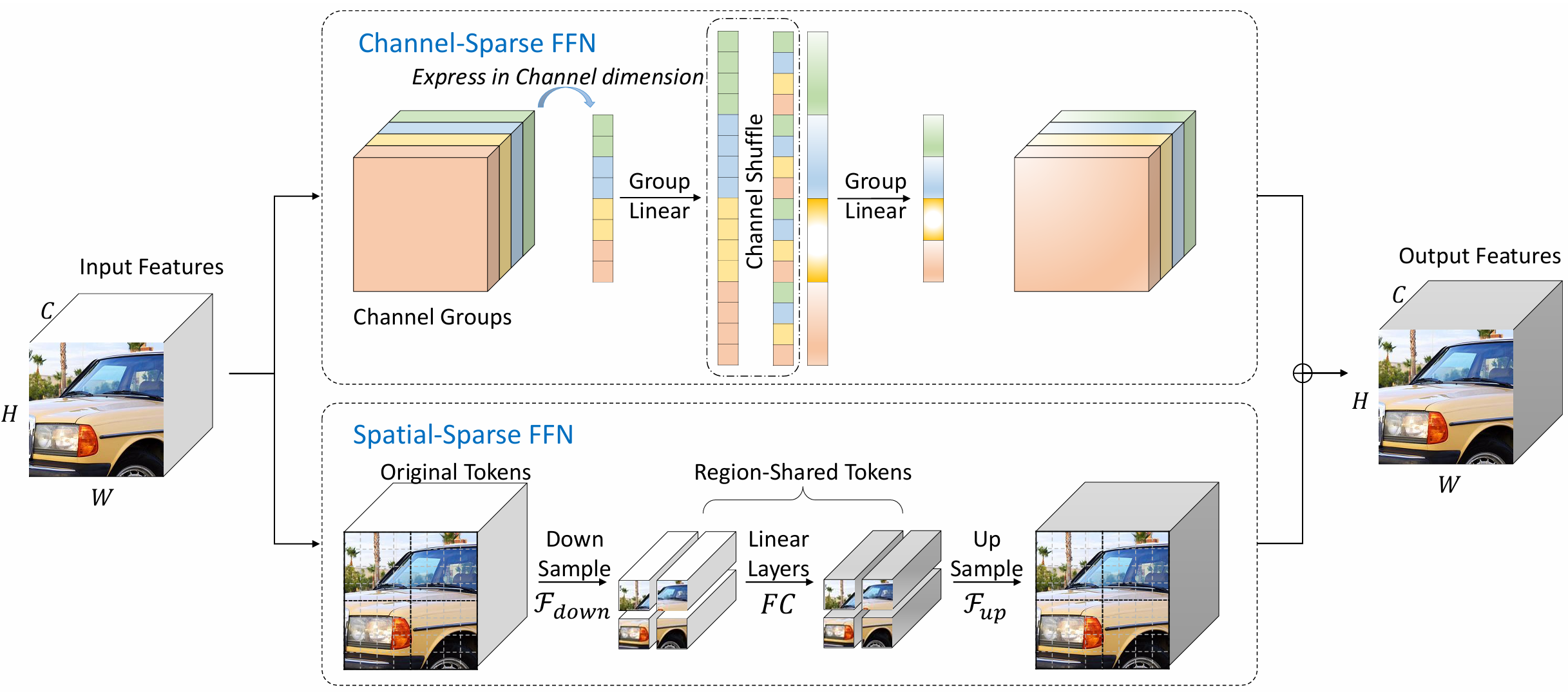
The devil is in details: Delving into lite ffn design for vision transformers
Zhiyang Chen, Yousong Zhu, Zhaowen Li, Fan Yang, Chaoyang Zhao, Jinqiao Wang, Ming Tang
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2024
In this paper, we find that the high-dimensional feed-forward networks occupies much computation cost in vision transformers. To this end, we introduce a lightweight, plug-and-play substitute, SparseFFN, that can reduce complexity in both channel and spatial dimension. SparseFFN can effectively reduce model complexity in a broad spectrum of vision models.
Efficient Masked Autoencoders With Self-Consistency
Haixin Wang, Lu Zhou, Yingying Chen, Zhiyang Chen, Ming Tang, Jinqiao Wang
IEEE Transactions on Circuits and Systems for Video Technology (TPAMI) 2023
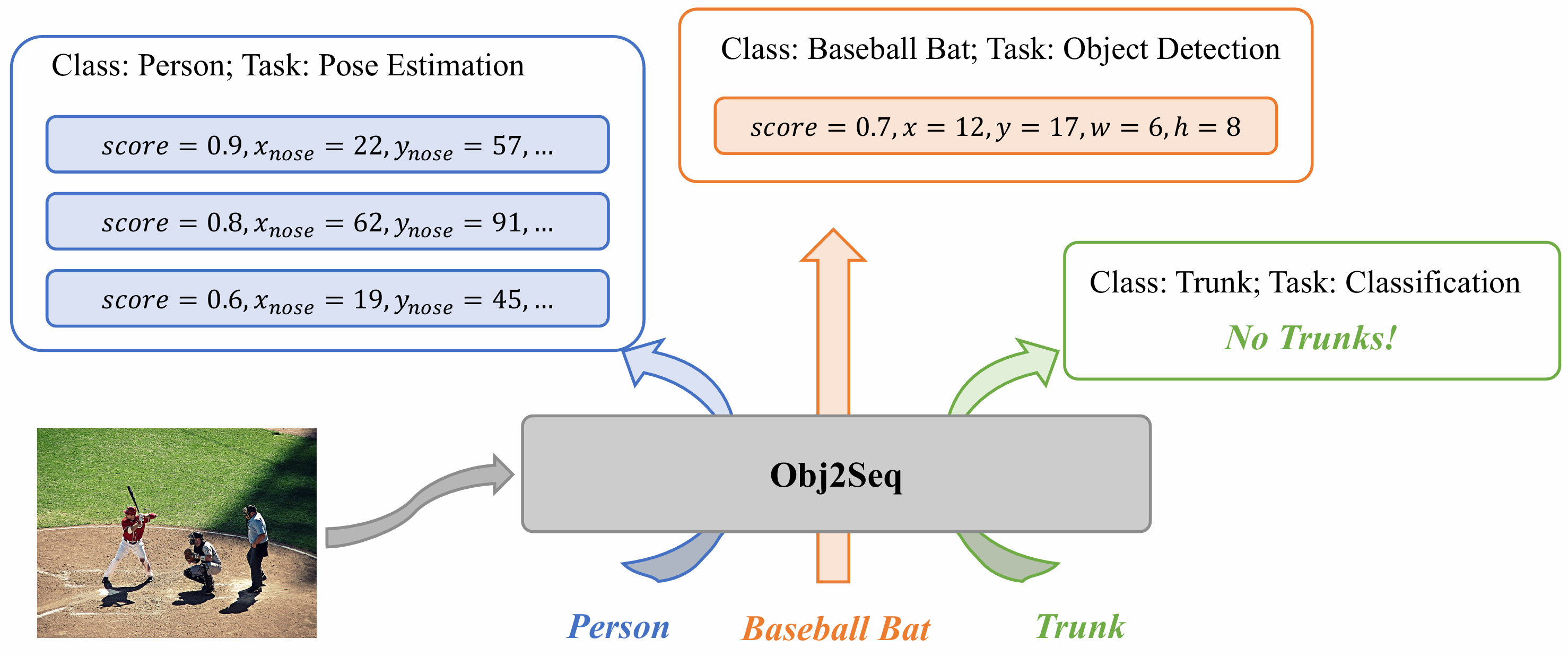
Obj2Seq: Formatting objects as sequences with class prompts for visual tasks
Zhiyang Chen, Yousong Zhu, Zhaowen Li, Fan Yang, Wei Li, Hanxin Wang, Chaoyang Zhao, Liwei Wu, Rui Zhao, Jinqiao Wang, Ming Tang
Neural Information Processing Systems (NeurIPS) 2022 Spotlight
We propose a general definition that encompasses a wide range of visual tasks, so that all their outputs can be decoded in an identical way: treating objects as fundamental units and generating multiple sequences based on the input image and class prompts. According to this, we build a language-guided general vision model that can meet diverse task requirements and achieve comparable performance with specialized models.

DPT: Deformable patch-based transformer for visual recognition
Zhiyang Chen, Yousong Zhu, Chaoyang Zhao, Guosheng Hu, Wei Zeng, Jinqiao Wang, Ming Tang
ACM Multimedia Conference (ACM MM) 2021 Oral
The fixed-size patch embedding in current vision transformers might overlook local spatial structures and extract inferior image features. To address this problem, we propose a new module (DePatch) which learns to adaptively split the images into patches with different positions and scales in a data-driven way, resulting in an enhanced backbone to extract more potent image features.
3. Self-Supervised Learning
Self-Supervised Representation Learning from Arbitrary Scenarios
Zhaowen Li, Yousong Zhu, Zhiyang Chen, Zongxin Gao, Rui Zhao, Chaoyang Zhao, Ming Tang, Jinqiao Wang
Computer Vision and Pattern Recognition (CVPR) 2024
Efficient Masked Autoencoders With Self-Consistency
Zhaowen Li, Yousong Zhu, Zhiyang Chen, Wei Li, Rui Zhao, Chaoyang Zhao, Ming Tang, Jinqiao Wang
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2024
UniVIP: A unified framework for self-supervised visual pre-training
Zhaowen Li, Yousong Zhu, Fan Yang, Wei Li, Chaoyang Zhao, Yingying Chen, Zhiyang Chen, Jiahao Xie, Liwei Wu, Rui Zhao, Ming Tang, Jinqiao Wang
Computer Vision and Pattern Recognition (CVPR) 2022
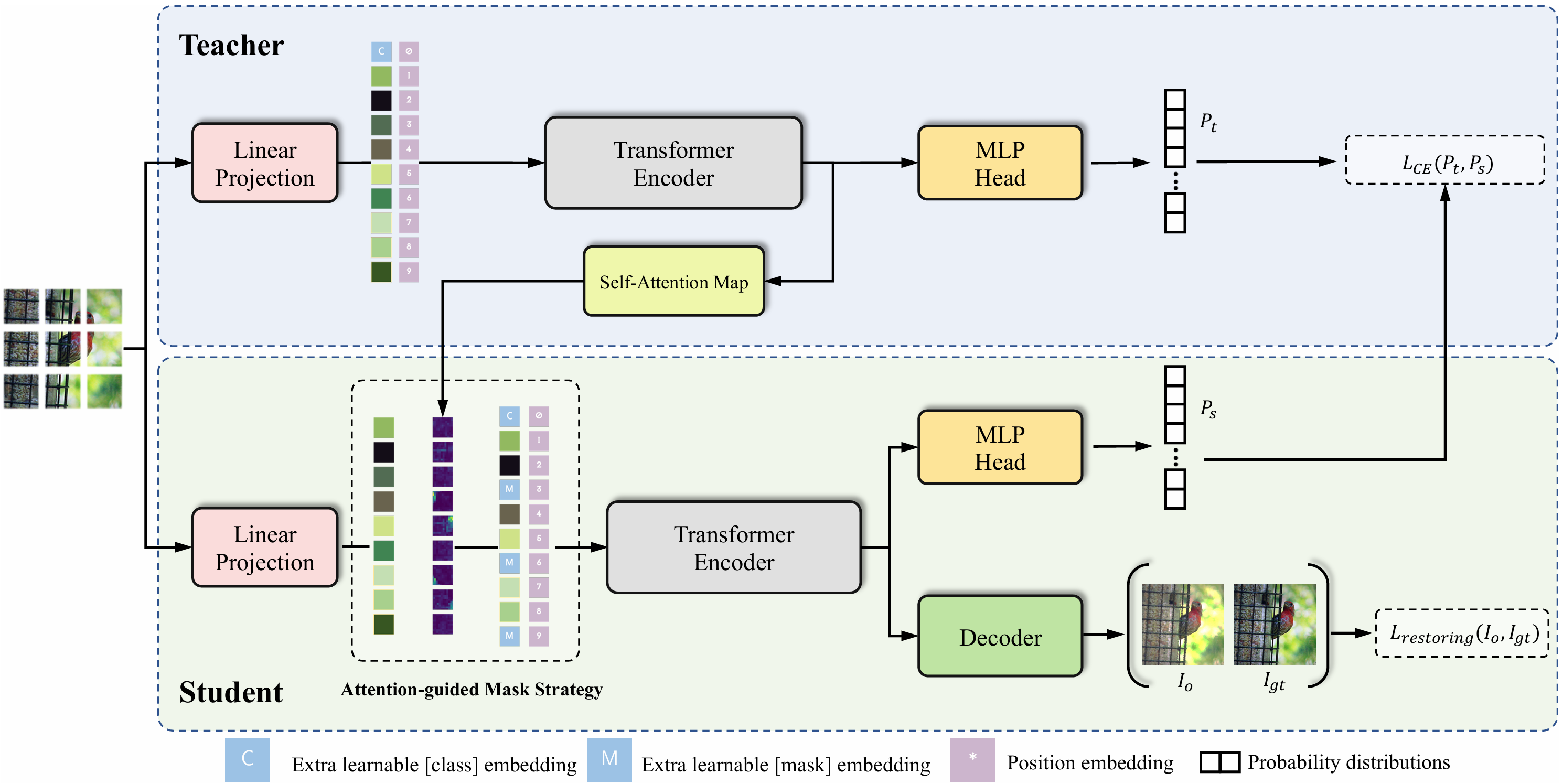
MST: Masked Self-Supervised Transformer for Visual Representation
Zhaowen Li, Zhiyang Chen, Fan Yang, Wei Li, Yousong Zhu, Chaoyang Zhao, Rui Deng, Liwei Wu, Rui Zhao, Ming Tang, Jinqiao Wang
Neural Information Processing Systems (NeurIPS) 2021
This paper is an early work to introduce Masked Image Modeling in self-supervised learning. MST utilizes self-attention map to mask background image tokens, and supervises with a pixel-level restoration loss to preserve fine-grained information, in addition to common contrastive learning. MST helps a lot in downstream tasks.